在介绍Adam之前首先介绍一下momentum和RMSprop优化算法。 一、momentum 1、指数加权平均数 指数加权平均数不仅考虑了当前数值也涵盖了以前的数据对现在的影响。 解释指数加权平均值名称的由来: 指数加权平均值的...
”优化 吴恩达 学习 学习笔记 深度学习 算法 算法原理“ 的搜索结果
为了方便学习深度学习课程,转载一个吴恩达老师的一个深度学习笔记,转载的网站是下面这个 https://blog.csdn.net/red_stone1/article/details/80207815 从去年8月份开始,AI界大IP吴恩达在coursera上开设了由5...
吴恩达机器学习笔记


为了方便学习深度学习课程,转载一个吴恩达老师的一个深度学习笔记,转载的网站是下面这个 https://blog.csdn.net/red_stone1/article/details/80207815 从去年8月份开始,AI界大IP吴恩达在coursera上开设了由5们课...
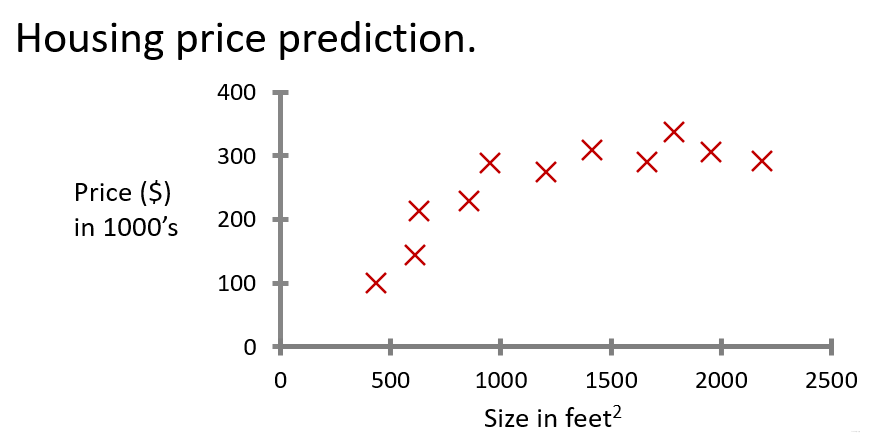
从上图可以看出,对于小规模的数据集,深度学习和机器学习它们的性能不一定谁好谁坏,只有在大规模上的数据集上时,深度学习才能体现出它更好的性能 损失函数是针对于单个样本的,而代价函数是针对一个batch的,...
当涉及深度学习优化算法时,我们通常会面临一个目标:最小化一个损失函数。这个损失函数衡量了模型预测与实际值之间的差距。为了找到最佳的模型参数,我们需要使用优化算法来调整这些参数,以便最小化损失函数。梯度...

为了确保√sdw和√sdb不为0,则训练过程将sdw+E(epsilon),E(epsilon)是一个非常小的非0的正数,例如:10……这样当db变化越大,sdb也会变大,那么由于计算b时,需要除以√Sdb,进而整体数值越小,那么缩小了b的震荡...
卷积神经网络

人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)
1.Mini-batch batch:之前所用的都是将m个...,这种梯度下降算法成为Batch Gradient Descent 为了解决这一问题引入 Mini-batch Gradient descent 它是将全部样本分成t份子集,然后对每一份子集进行一个单一的训练...
吴恩达-强化学习笔记


吴恩达深度学习——读书笔记
标签: 深度学习

如果你听说过端对端深度学习,你也会在第三门课中了解到更多,进而了解到你是否需要使用它,第三课的资料是相对比较独特的,我 将和你分享。在第一门课中(神经网络和深度学习),你将学习神经网络的基础,你将学习...



引言:个人当前研究倾向是智慧...公开课看:吴恩达coursera《机器学习》,李飞飞斯坦福《卷积神经网络》,李宏毅台湾大学《机器学习》/《深度学习》。 竞赛:https://beetl.ai/data; 官方代码,这个方法有70%准确率。 ...
本节讨论深层神经网络,包括深层神经网络的结构、深层神经网络前向传播和反向传播过程、需要深层神经网络的原因、神经网络参与超参数、神经网络与人脑简单对比。
(一)神经网络与深度学习 一、概论 神经网络: 神经元:◯表示非线性函数 神经网络:像乐高积木一样堆叠神经元 用神经网络进行监督学习(目前神经网络的落地方向比较成熟) 结构化数据(海量数据, 广告,赚钱) ...

推荐文章
- I2C知识大全系列六 —— I2C应用之Linux下的I2C_linux控制i2c应用编程-程序员宅基地
- 微擎URL路由_noloading: true, noredirect: true-程序员宅基地
- 关于arduino程序编译成功但上传失败的情况_arduino编译完成但上传错误-程序员宅基地
- 机器学习中的数据预处理_机器学习数据预处理顺序-程序员宅基地
- 谈一次java web系统的重构思路_java web 如何做系统重构-程序员宅基地
- 如何一文认识 AngularJS_angularjs理解-程序员宅基地
- 编写C语言程序,输入每个学生的学号和身高,保存在二进制文件中,并统计每个身高的人数打印出来...-程序员宅基地
- R语言 最优子集选择与K折交叉验证_最优子集法做交叉验证-程序员宅基地
- antd From 中 Form.Item里含有自己封装的组件,获取不到值的解决方法_from.item 拿到组件无法获取参数-程序员宅基地
- 爬虫的基本原理-程序员宅基地